I thought the observation was always that instruction set was not such a big difference in high performance CPUs next to manufacturing technology which was by far the first order effect. It would be expected for a high performance ARM CPU to reach roughly the same performance in that case (AMD is 1 generation behind here, I think Intel is 2).
Is there really "chipheads" who are predicting ARM ISA to buck this trend and start pulling ahead at equivalent technology nodes? By what mechanism do they believe this will happen, do you know?
1. The instruction set isn't so much a performance thing as much as a thing that bites you with power usage (you need to have a big fat decoder on all the time in the worst case). The widest X86's can only dispatch 75% of the instruction per cycle but X86 instructions can do more, so you'd have to check a specific benchmark.
2. I want X86 to die more because it's fucking ugly than performance as per se. ARM is not a simple ISA, so although you won't be writing a disassembler in 10 minutes like RISC-V, aarch64 is still much less insane than X86 with all the extensions.
> The instruction set isn't so much a performance thing as much as a thing that bites you with power usage (you need to have a big fat decoder on all the time in the worst case).
Eh, it's overhead, but isn't massive overhead. Power usage is much more a function of how the chip was designed.
The vast majority of developers will never even see assembly for x86 or ARM. Compiler developers and those need to hand optimize code may care but for everyone else it's a black box.
The unwashed masses don't have to care and won't actually use the performance, I'm not that bothered whether they care or not, although it's worth saying that X86 is such a mess that hiding instructions at weird alignments is a valid obfuscation technique - i.e. it's not just aesthetics/performance.
I’m not part of the category you’re part of - but after learning 6502, Z80 and 68K, when it came time to look at the 80x86 I gave it a hard pass and learned C instead. I kinda assumed x86 would die a natural death. Wrong!
Sadly I have not programmed in assembly since, and I put it down to how ugly the ISA was.
https://microcorruption.com/login might be one place to start, but it's got a slightly different focus, but if you broadly want to learn lower-level stuff it's a place to start.
We'll get a live test of this very soon - Zen4 is going to be going head-to-head against Apple A16 (Apple's next core architecture) on TSMC N5P next year.
Does anyone expect x86 to close a factor-of-6 perf/watt difference? (from Anandtech's M1 Max preview) A factor-of-2-to-3 IPC difference? And that's just A15, not against the next-gen A16.
Node makes a big difference, it doesn't close up a factor-of-3 IPC gap in a single node though, that's facially ridiculous. Name a full-node shrink+architectural step that has tripled IPC in the last 10 years. Now name one that has done it while cutting power in 1/6th.
At that point we will see the goalposts shift again and it will be "well, x86 could do it if they wanted but Apple is just more willing to spend more transistors..."
Fact of the matter is the x86 makes it very difficult to spend those transistors efficiently - otherwise it already would have been done. If it was such an obvious gain to just spend those extra transistors, then surely AMD would have done it, if nobody else.
Everyone acknowledges x86 has some problems, but the other thing is that they've already mostly played their hand trying to fix those problems, the known solutions like instruction cache have mostly been exhausted at this point. The idea that AMD and Apple can just triple IPC at a whim but they've chosen not to do so for some reason, is facially ridiculous.
I know what Jim Keller said but the math just doesn't add up on it for me. OK, full node shrink, great, even if that doubles your transistor count at iso-power, or even doubles it at a little less power, that doesn't double your IPC let alone triple it, and it doesn't close a factor-of-6 perf/watt gap.
I don't really know where to start on this. SKUs that target very different markets are necessarily going to have different performance and efficiency tradeoffs. And core which target different cycle times are going to be able to achieve different IPC. This clearly confuses the basis of performance and different freq/ipc design points.
I also didn't suggest Apple would never have the best chips ever. Clearly all else being equal if ISA was irrelevant and you had 1 ARM competitor and 1 x86 competitor then sometimes the ARM CPU is going to be the better of the two.
I'm asking is there some continued effect by which people think ARM is going to continue to pull ahead. Is it going to remain < 5%, or is there some turning point where that will start to increase? I'm no expert on this, but there are experts who don't seem to think that there will be such an inflection point.
> I don't really know where to start on this. SKUs that target very different markets are necessarily going to have different performance and efficiency tradeoffs. And core which target different cycle times are going to be able to achieve different IPC. This clearly confuses the basis of performance and different freq/ipc design points.
see my response elsewhere, but these aren't unrelated problems: Apple has higher IPC at a lower power-per-core. You can slide around where on the scale x86 falls - maybe you can match perf/watt but then you're getting wiped by a factor of 3 on performance, and you can match on performance but then you're getting wiped by a factor of 6 on perf-watt. You can't do both at once.
There simply isn't enough transistor gain from a single node shrink there to clear that much of a gap, basically Apple is also seeing much better performance-per-transistor and that's a harder gap to close.
> I'm asking is there some continued effect by which people think ARM is going to continue to pull ahead. Is it going to remain < 5%, or is there some turning point where that will start to increase? I'm no expert on this,
where in the world are you getting that this is <5% gap?
again, 3990WX is an absolute best-case scenario here, that is putting a laptop Apple chip up against a HEDT-class (really, server-class) CPU with 6 times the silicon area and five times the TDP, and all it can do is match it. Mac Pro is the Apple competitor to those chips, and you'll see it slide back into the lead again.
and again, task energy as a measurement favors getting it done faster over pure perf/watt. It's still a 280W TDP / 350W PPT chip against a 60W laptop chip, and it has way more silicon, it's the best case scenario and all they can do is match the M1 in task energy.
That's actually still an extremely good outcome for the M1 and the 40-core Mac Pro is going to slide back over the top again.
> see my response elsewhere, but these aren't unrelated problems: Apple has higher IPC at a lower power-per-core. You can slide around where on the scale x86 falls - maybe you can match perf/watt but then you're getting wiped by a factor of 3 on performance, and you can match on performance but then you're getting wiped by a factor of 6 on perf-watt. You can't do both at once.
I'm not sure how you established that. IPC and picoseconds available per cycle are intrinsically linked. Talking about IPC in isolation is nonsense, particularly when comparing a core that makes less than half the cycle time.
> where in the world are you getting that this is <5% gap?
I just mean the rule of thumb for the "x86 tax", not any specific device. The full thread should have context here, I'm not saying Apple is or is not ahead in a particular instance, I'm asking about more general trends of device performance and ISA.
“Intrinsically linked” doesn’t mean anything, if you want to make an argument then make it.
I’ve already made mine - Anandtech shows a factor of 6 difference in perf/watt between a 11980HK and a M1 Max at peak performance, and this likely translates into a ~factor of four-ish difference in perf/watt and IPC at iso-power. That’s a performance gap that is unlikely to be closed by a node shrink - there is a large architectural gap there. Sure, Apple is probably using tighter pitches as well, but that doesn’t add up to a factor of 4 difference either.
If you have one processor that is doing 4 times the performance at iso clocks, and 2.2x the performance with both processors running at peak clocks, the "megahertz myth" isn't applicable, one of those processors is just faster than the other.
We will see next year, with Zen4 and A16 (apples next core) going head to head on N5P. I strongly doubt Zen4 will even get close.
> I just mean the rule of thumb for the "x86 tax", not any specific device.
Ah, so you are conflating “the amount of transistors spent on x86 decoding” with “the architectural impact that x86 has on performance”.
Unfortunately those are not the same thing. To make the car analogy, how much of your car’s engine bay is spent on aspiration? Probably 5%, maybe 10% right? So obviously aspiration is not important to a car’s performance output at all? And a different method of aspiration would not affect performance at all, a turbocharged car performs almost identically to a naturally aspirated car?
That’s the argument you’re making by focusing on number of transistors spent decoding instead of the impact on the rest of the design. Having a much higher “rate of feed” enables much higher-performance optimizations in the rest of the design - like a much much much deeper reorder buffer.
And just like with cars - that 5% or so of the processor is a key enabling factor that can produce gains of 2x in the rest of the processor, because it’s the only way to keep an engine that is 2x as powerful fed. It doesn’t, itself, produce all that much speedup, but you can’t design bigger engines without clearing that bottleneck. Even if it’s only 5% you can’t do those same designs naturally aspirated.
Similarly, even if the decoder is only 5% of the x86 design, it doesn't mean it's not strangling the ability to scale the rest of the design.
The biggest die shrink in recent times was probably Intel's 22nm jump to FinFET (Global Foundries made a decent jump at 14nm, but it couldn't save bulldozer). Rather than the usual 50-70%, Intel claimed transistor density DOUBLED.
Haswell got a very modes (<10%) performance improvement and an equally modest 10% lower power at load (though almost 25% at idle).
Sandy Bridge did much better in performance (up to 40% in some benches) and also did decently well in power consumption despite using the same node.
AMD saw massive increases with Zen on the same 12nm node. The also saw almost 20% IPC increases from Zen 2 to Zen 3 despite both being on the same N7 node
If anything, history shows that node shrinks are always overrated at improving power and performance.
> Does anyone expect x86 to close a factor-of-6 perf/watt difference?
The one number that surprised me in this review was that the perf/W of Threadripper for the rendering phase: it is very close to the M1 Max. I understand that the numbers are not apples to apples because of the total laptop vs CPU-only comparison, but the power consumption of the Threadripper CPU itself is very high and probably takes the lion's share of the overall power consumption. And that's for a previous generation Threadripper.
task energy comparisons are usually won by the processor that gets it done fastest in absolute terms: because of the overhead of the rest of the system, it takes a really big perf/watt win to come out ahead of the system that maybe isn't as efficient in actual watts but gets it done in half the time, because you pay the system overhead for a shorter period of time.
it's also a 128-thread processor being put against a 8+2 thread processor, and that's the closest thing to something that will outweigh Apple's IPC advantage here: super wide processor clocked super slow, and unlike the more realistic comparisons (laptop processors, etc) the Epyc has deployed over four times as much silicon just to match the M1.
This is the absolute best-case scenario for x86 - they get six times as much silicon and 16 times as many threads and all they can do is match it.
Do the comparison again against the Mac Pro 40-core chip when it comes out and you'll see A15 pull ahead again.
The 3990x is not designed for energy efficiency, on an older node, and on an older architecture... uses 3kWh vs Apples 2kWh (using a very flawed methodology).
An yet you're claiming Apple has a 3-6x power efficiency advantage.
Hmm? Perf/watt isn’t the same thing as task energy, it sounds like you’re the one confused here. As I said, task energy (which is what’s measured in the OP) heavily favors “getting it done quicker” as well as this task being embarrassingly parallel such that the 3990WX can get all 128 threads into play. It’s basically a “race to sleep” benchmark not a perf/watt benchmark with processors that are that disparate.
For a task energy test - which is not the same thing as a perf/watt test - this is completely loading the dice in favor of x86 and M1 still manages to match it. That is an extremely good result for putting a laptop chip against a top of the line HEDT processor in a test that is normally all about race to sleep.
> An yet you're claiming Apple has a 3-6x power efficiency advantage.
I’m not the one claiming anything, if you disagree with Anandtech’s numbers go take it up with them. The numbers don’t change just because you find them uncomfortable.
> In multi-threaded tests, the 11980HK is clearly allowed to go to much higher power levels than the M1 Max, reaching package power levels of 80W, for 105-110W active wall power, significantly more than what the MacBook Pro here is drawing. The performance levels of the M1 Max are significantly higher than the Intel chip here, due to the much better scalability of the cores. The perf/W differences here are 4-6x in favour of the M1 Max, all whilst posting significantly better performance, meaning the perf/W at ISO-perf would be even higher than this.
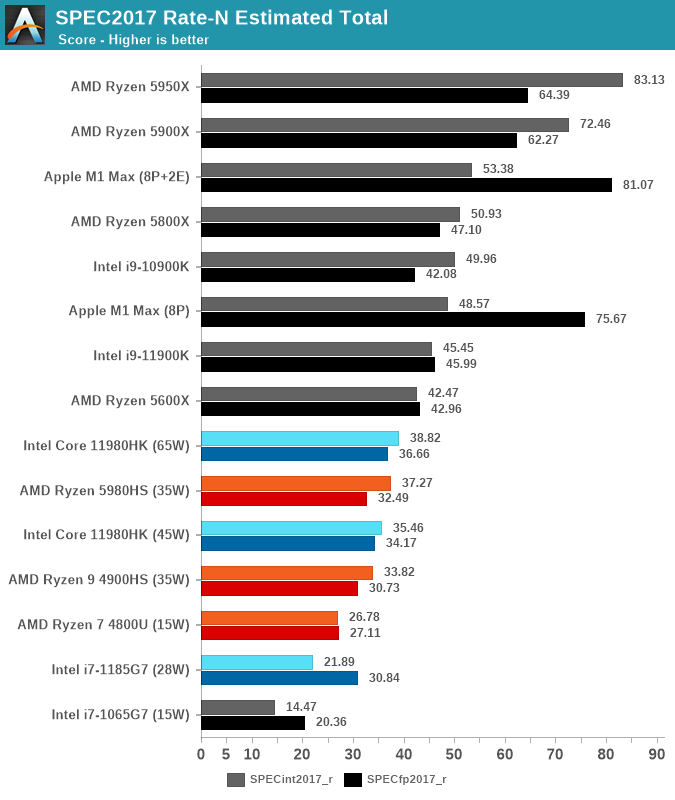
> In the SPECfp suite, the M1 Max is in its own category of silicon with no comparison in the market. It completely demolishes any laptop contender, showcasing 2.2x performance of the second-best laptop chip. The M1 Max even manages to outperform the 16-core 5950X – a chip whose package power is at 142W, with rest of system even quite above that. It’s an absolutely absurd comparison and a situation we haven’t seen the likes of.
And again, that’s with it running at half the clock and half the threads of its laptop peers, so IPC is something like 8x higher in those scenarios.
That is not the kind of gap you close up with a node shrink or tightening pitches a bit. Hackernews experts know best though.
Next year Zen4 and A16 will be on the same node, and then it’ll be another excuse for why x86 is still getting dumpstered. Just keep the goalposts on wheels, you’ll need it.
> Perf/watt isn’t the same thing as task energy, it sounds like you’re the one confused here.
How do you calculate Perf/watt if not Task/Task Energy?
> As I said, task energy (which is what’s measured in the OP) heavily favors “getting it done quicker”
Which x86 can do.
> It’s basically a “race to sleep”
Oh no, it gets the task done faster!
> I’m not the one claiming anything, if you disagree with Anandtech’s numbers go take it up with them.
I have no issue with Anandtech, since they made no such claim. I read the article, you're badly misquoting it.
> And again, that’s with it running at half the clock and half the threads of its laptop peers, so IPC is something like 8x higher in those scenarios.
None of which is ultimately important.
> That is not the kind of gap you close up with a node shrink or tightening pitches a bit. Hackernews experts know best though.
Look at the results again. For example for SPEC2017 ST the Apple M1 MAX is essentially tied with the 5950x.
Sure the M1 Max might be more energy efficent (though by how much you'd need to measure) - but remember it's a massively larger chip, a whole year newer, and on a newer node.
For MT we see the M1 max bearely beat a 5800X for int, and do significantly better for floating point - which shows different priorities of design.
Again, take a 5800X, shrink it down, add another FPU, and it beats a M1 max hands down.
> Next year Zen4 and A16 will be on the same node, and then it’ll be another excuse for why x86 is still getting dumpstered.
Except x86 isn't getting dumpstered.
You're just cherry picking specific comparisons that make M1 look great, and then ignoring all contrary information.
I mean, I could the the Borderlands 3 1080p benchmark, and say that the M1 got 21.1FPS to the GE76's 100, and therefore x86 is ~8 times faster.
It wouldn't be honest (I'm deliberately chosing the worst M1 chip, and picking a workload that really favors x86) - but I could do it.
But I don't, because it's not honest nor is it helpful.
Chip Core# TDP 1-Core 1-Core All-Core All-Core
Power Freq Power Freq
3990X 64 280 W 10.4 W 4350 3.0 W 3450
3970X 32 280 W 13.0 W 4310 7.0 W 3810
3960X 24 280 W 13.5 W 4400 8.6 W 3950
3950X 16 105 W 18.3 W 4450 7.1 W 3885
As you can see, going from 4.35GHz down to 3.45GHz reduces power consumption by over 3x. Further, per-core power usage of the 3990x is very low overall.
This lower clock and lower per-core performance gives higher overall performance per watt.
I have an AMD Ryzen 5900X and it is nearly the same in single core and much faster multi-core (12 core). So I don't think it's accurate to say that x86 needs 4x the silicon just it match the M1.
So why don't you write up an article and provide some benchmarks? You'll win lots of internet points, at least on Hacker News, as a lot of people seem pretty upset that Apple's new silicon is killing it.
It is very relevant: people keep bringing up the "x86 loses because it is clocked higher" (you did so yourself!) but the thing is, sure, clock that x86 down and then instead of matching in performance and losing heavily in perf/watt you lose heavily in performance and match in perf/watt.
The fact of the matter here is that Apple is getting much better IPC at a much better power-per-core, and that is the real architectural gap. You can slide around where on the scale that x86 falls, but there isn't enough gain from a full node shrink to close a factor-of-6 perf/watt gap and a 3x IPC gap.
CPUs are designed to hit a certain clock rate. The target frequency influences the design of literally every circuit in the CPU. Downclocking a CPU is not the same as designing it for a lower frequency. An x86 CPU is designed to run at ~5GHz in its highest turbo mode. Simply reducing the frequency in the BIOS does not undo all the tradeoffs the architects made that deliberately sacrificed IPC for frequency.
You could make a very wide CPU indeed if you decided to run it at 100MHz. That would be obviously stupid, though, because it is the product of IPC and frequency that matters.
It certainly looks like Apple has made the better tradeoff. However, you can only tell that from the benchmarks. Either going wider or going faster are valid approaches.
This of course has the subtle implication that it’s equally easy for x86 to go as wide as ARM, and it’s not.
Yes, it’s true that x86 often relaxes pitch, that doesn’t make up for a factor of 6 perf/watt difference like Anandtech measures.
Like I said, I guess we’ll see, Zen4 and A16 will be on the same node next year. By that time the goalpost will move to something else, like this “x86 isn’t designed for power efficiency” defense.
Why do you think x86 can't go as wide as ARM? (I predict your answer will involve something about decoders and nothing about uop caches.)
What goalpost have I moved? I have said one (true) thing: that you should judge by performance rather than by implementation details. You are falling victim to the Megahertz Myth, just the other way 'round.
OK, here’s the performance. Factor of 2.2X over its peers (other laptop SKUs) in multithreaded performance, going head to head with 5950X in some (floating-point) scenarios.
Why do you think megahertz myth is relevant here? Core for core A15/M1 is plainly faster than any of its peers, ignoring clocks, and it is even farther on top when you do look at clocks (i.e. IPC). It doesn’t matter at all which way you look at it, unless you are putting M1 up against HEDT SKUs like 3990WX - there are a few non-peer scenarios like that it only ties x86 in, like OP looking at task energy (3990WX gets to use 280W TDP/375W PPT and race to sleep) but that’s still an incredibly good outcome considering the loaded test, and Mac Pro with its 32+8 configuration will almost certainly be back on top in the “peer” comparison scenario.
It’s amazing how much breath was wasted on “IPC is what really matters” when Ryzen came out and now it’s “the other side of the megahertz myth” when Apple is on top. Ryzen was never even remotely close to being in the lead on IPC compared to where Apple currently is.
Even at iso-power you are looking at a factor-of-3-to-4 difference in performance - I was being generous with the “only 3x IPC” thing. That is what Anandtech measured in their review. And that still means a gap of 4x perf/watt - which is better than 6x for sure, but it doesn’t mean low-clocked x86 magically beats A15.
> It’s amazing how much breath was wasted on “IPC is what really matters” when Ryzen came out and now it’s “the other side of the megahertz myth” when Apple is on top. Ryzen was never even remotely close to being in the lead on IPC compared to where Apple currently is.
IPC is what "really matters" when all the chips you're evaluating are capping out at pretty similar frequencies. When there's a 30% difference in frequency then you need to use instructions per second, and evaluate it with the context of different wattages and different benchmarks.
Sigh. IPC matter when you are comparing within the same architecture, as that means the comparative performance vs other cores of the same architecture ends up (somewhat simplified) as IPC * frequency. It is utterly irrelevant when comparing across architectures as the instruction sets are different. IPC matter when comparing Ryzen to Intel, and between A15 and A16, but it doesn't matter at all when comparing A15 to anything x86-based.
>OK, here’s the performance. Factor of 2.2X over its peers (other laptop SKUs) in multithreaded performance, going head to head with 5950X in some (floating-point) scenarios
Finally a sensible comparison! As I said, it is quite impressive.
>it doesn’t mean low-clocked x86 magically beats A15.
Nor did I ever say it would.
What I have said is a simple truth: leading on IPC and trailing on frequency is not obviously an advantage. I don't understand what it is you think I said. Pretty much everything you are writing is a non-sequitur.
Would you please stop posting in the flamewar style to HN? I just had to warn you about this elsewhere in the thread. This is not cool.
You obviously know stuff about this topic and that's great, but the benefit of that is smaller than the damage you cause by flaming. Would you please review https://news.ycombinator.com/newsguidelines.html and stop this going forward? We'd appreciate it.
Not a chiphead, but saw this in the article that might be a reason ARM is better for this kind of thing:
"The theory goes that arm64’s fixed instruction length and relatively simple instructions make implementing extremely wide decoding and execution far more practical for Apple, compared with what Intel and AMD have to do in order to decode x86-64’s variable length, often complex compound instructions."
Not sure it's true, not an expert. But it doesn't sound wrong!
The fixed width decoders have always been a commonly cited advantage of fixed width, and to some degree it must be true. But this is not a recent thing, the "common wisdom" about instruction format not mattering too much still very much applies here.
Pre-decode lengths or stop-bits and more recently micro-op caches have been techniques that x86 has used to mitigate this and improve front end widths, for example.
People like Jim Keller (who has actually worked and lead teams implementing these very processors at Apple, Intel, and AMD!) basically say as much (while acknowledging decode is a little harder, in the large scheme of things on modern large cores it's not such a big deal):
> A consistent 5% win is pretty huge for certain industries.
Are you referring to Andy Glew's thread? He said perhaps 5%, but he also went on to say probably less than 5% for basically the lowest-end out of order processor that was fielded (A-9), not what you would call a high performance core (even then 10 years ago). On today's high performance cores? Not sure, extrapolating naively from what he said would suggest even less. Which is backed up by what Jim Keller says later.
So << 5%, which is significantly less than process node generational increases.
I'm not saying ARM won't leapfrog x86, I'm just asking what the basis is for that belief, and what those who believe it think they know that the likes of Jim Keller does not.
If it's an argument about something other than details of instruction set implementation (e.g., economics or process technology) then that would be something. That is exactly how Intel beat the old minicomputer companies' RISCs despite having "x86 tax", is that they got revenues to fund better process technology and bigger logic design teams. Although that's harder to apply to Apple vs AMD/Intel because x86 PC and server units and revenues are also huge, and TSMC gives at least AMD a common manufacturing base even if Apple is able to pay for some advantage there.
Most of the chip-heads' deep hatred for x86 comes from the number of pain-points for dealing with its ISA.
In terms of actual raw performance the instruction set is extremely secondary to about 10 other architectural choices.
The reason Apple is getting such performance is because it's caught up with all the cutting edge techniques Intel and AMD use, and a few more, and implemented them inside its core architecture.
The two primary mechanisms I am aware of are drastically simpler instruction decoding and lack of backwards compatibility. Both of these save on power and area, allowing those budgets to be spent elsewhere. Often times on wider instruction decode, extra execution units, better branch prediction, etc.
These budgets are much tighter on a mobile chip, but are still relevant on desktop design.
I mean, VLIW is fantastic as long as you have very predictable workloads with high parallelism and little branching that are very easily statically scheduled.
If you want to design a DSP or something, where you know it’ll be 100% saturated all the time with an absolutely predictable workload, it’s extremely efficient. Same for AMD Terascale GPUs back in the days before async compute and other GPGPU style tasks took over.
{kind=link}
Is there really "chipheads" who are predicting ARM ISA to buck this trend and start pulling ahead at equivalent technology nodes? By what mechanism do they believe this will happen, do you know?